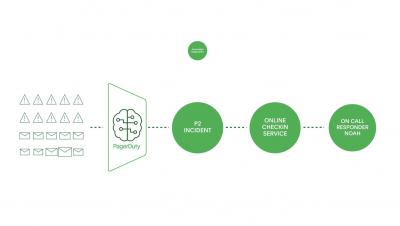
Integrating Shipa with PagerDuty
In this Shipa Short, we go through how to quickly wire a Shipa to a PagerDuty Alert. This is especially valuable as Shipa Insights can pick up on compliance and security violations.


The latest News and Information on Incident Management, On-Call, Incident Response and related technologies.
Imagine having the ability to instantly know when a Kubernetes compliance or security violation occurs. Now you can with Shipa Insights. Coupling Shipa Insights with the robust notification and alerting capabilities of PagerDuty makes this very possible. Shipa has the capability of sending fine-grained events externally e.g to PagerDuty. Now with the power of Shipa Insights, you have the capabilities to alert on policy violations. Let’s take a look at gettings started.
Service ownership is a DevOps best practice where team members take responsibility for supporting the software they deliver at every stage of the development lifecycle. This level of ownership brings development teams much closer to their customers, the business, and the value being delivered. Service owners are the subject matter experts (SMEs) for their services – and in a service ownership model, they are also responsible for responding to any production issues.
As an IT Ops exec, imagine your jubilation upon learning that after a year of hard work across your NOC, DevOps and SRE teams, you are able to automate incident response by 25%. You’re elated as you enter your CTO’s office to share this information, and their response is.
There are a number of lessons I learned guiding weeks-long backcountry leadership courses for teens that I carried with me into my roles in incident management. In this blog post, I’ll share three that stand out.
Hospitals that adopt electronic health records (EHR) to optimize clinical workflows face the decision of how to integrate EHR alerts into their workflows. The rationale is to surface actionable data from EHR systems and present healthcare providers with this information to supplement their day-to-day clinical decisions.
This day started a bit abruptly, with several services experiencing outages due to a Cloudflare outage. It started approximately at 06:34 AM UTC. Check the official announcement. What came next was a domino effect through many popular services over the internet. Major services like Gitlab, Notion, Hubspot, Digital Ocean, Monday, Recurly, and a lot more. We registered incidents from 230 services between the outage was published until it was marked as resolved.
Is your IT team ready to respond to an increasing volume of data security incidents? According to the 2021 Annual Data Breach report from the Identity Theft Resource Center, 2021 saw a record number of data breaches, representing a 68% increase from the year prior. The most recent Cost of a Data Breach report from IBM shares the Ponemon Institute’s finding that the average data breach is a $4.24 million expense, up 9.8% from the previous year.